Federated Learning—a primer
Also posted on Medium here.

It’s already in our keyboards. It’s coming for our website cookies. It’s used in clinical trials to connect siloed patient data. Yet not many technologists have heard of federated learning. Let’s change that.
Federated learning is a type of machine learning that can train models on data that are not shared by its owners. Instead of sending all the data to a central cluster for (machine learning) model training, the model is trained directly on users’ devices. Only model updates are shared. This unlocks unprecedented benefits in privacy. Internet businesses may stop collecting user data. More excitingly, industries which have long resisted machine learning for privacy and legal reasons — medicine, finance, governance — may now get to utilize machine learning!
Why then is federated learning less buzzed about than its decentralized peer, cryptocurrencies? One reason is that it’s a mouthful to explain. Since presenting my thesis on federated learning two years ago, I’ve found that the best way to explain it is to understand how the data flow differs in the federated case compared to the centralized case.
Centralized machine learning
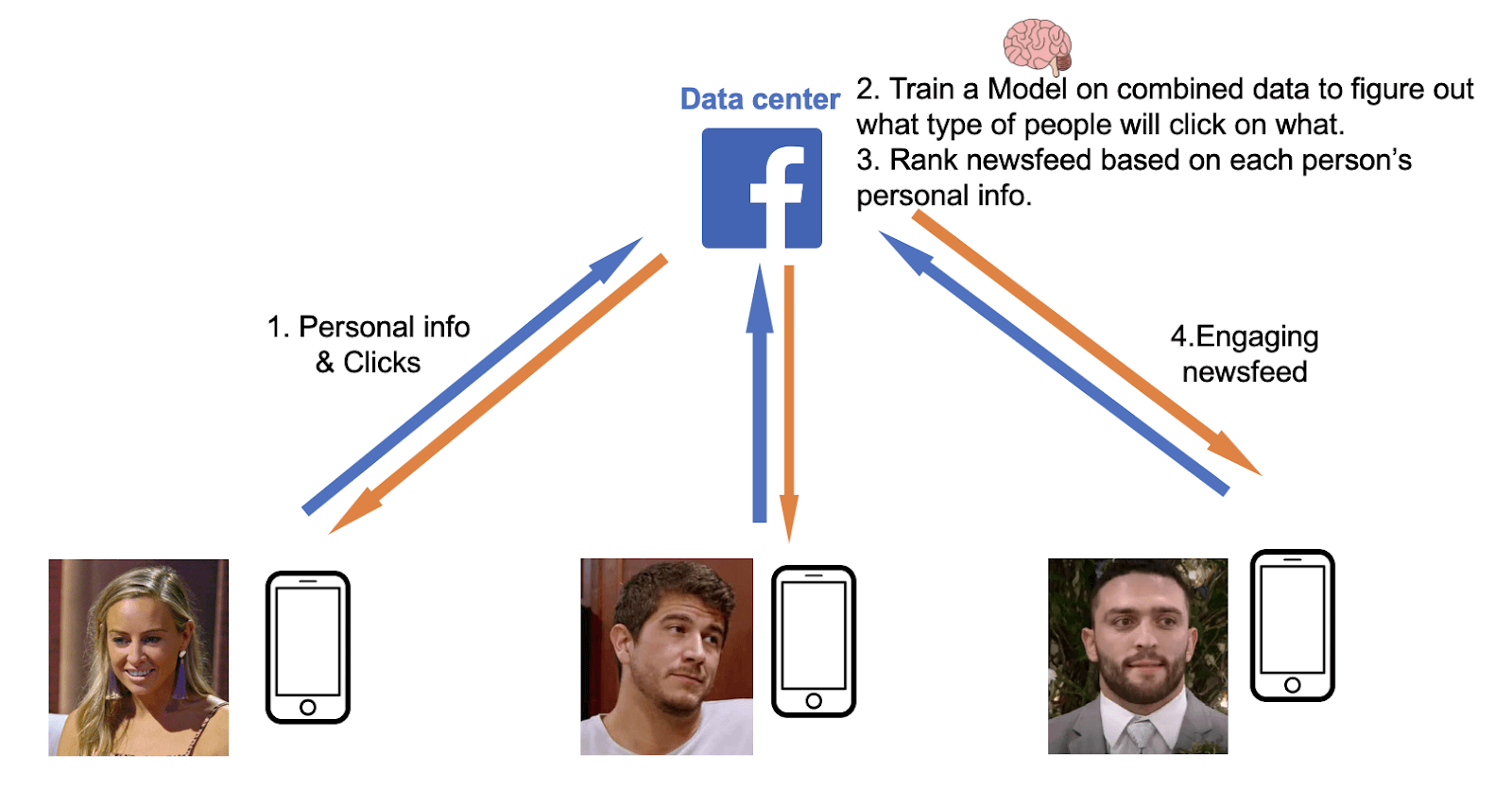
Today, it is typical to send our sensitive data to corporations in exchange for smarter software. Take how Facebook makes your newsfeed more engaging. Step 1: By using the Facebook newsfeed, we send our demographic information and clicks to its data centers. Step 2: Facebook trains a model on our aggregated data to figure out what types of people will click on what. It then ranks a news feed based on our personal information. Step 3: It loads us that newsfeed.
You start to see the problem. One hack on the central source happens and our data becomes public. The NSA has been reading our Google information — location data, emails, photos. Someone leaked our DNA. The internet is more secure than ever, but the cost of any hack has exploded as more and more personal information has been aggregated by so many firms. It’s why healthcare providers, financial institutions, and governments prefer their data stay on devices they own. They would rather their data be safely siloed even if it means giving up on machine learning.
Federated Machine Learning
Federated learning gets us the best of both worlds. Your data stays on your device the whole time.
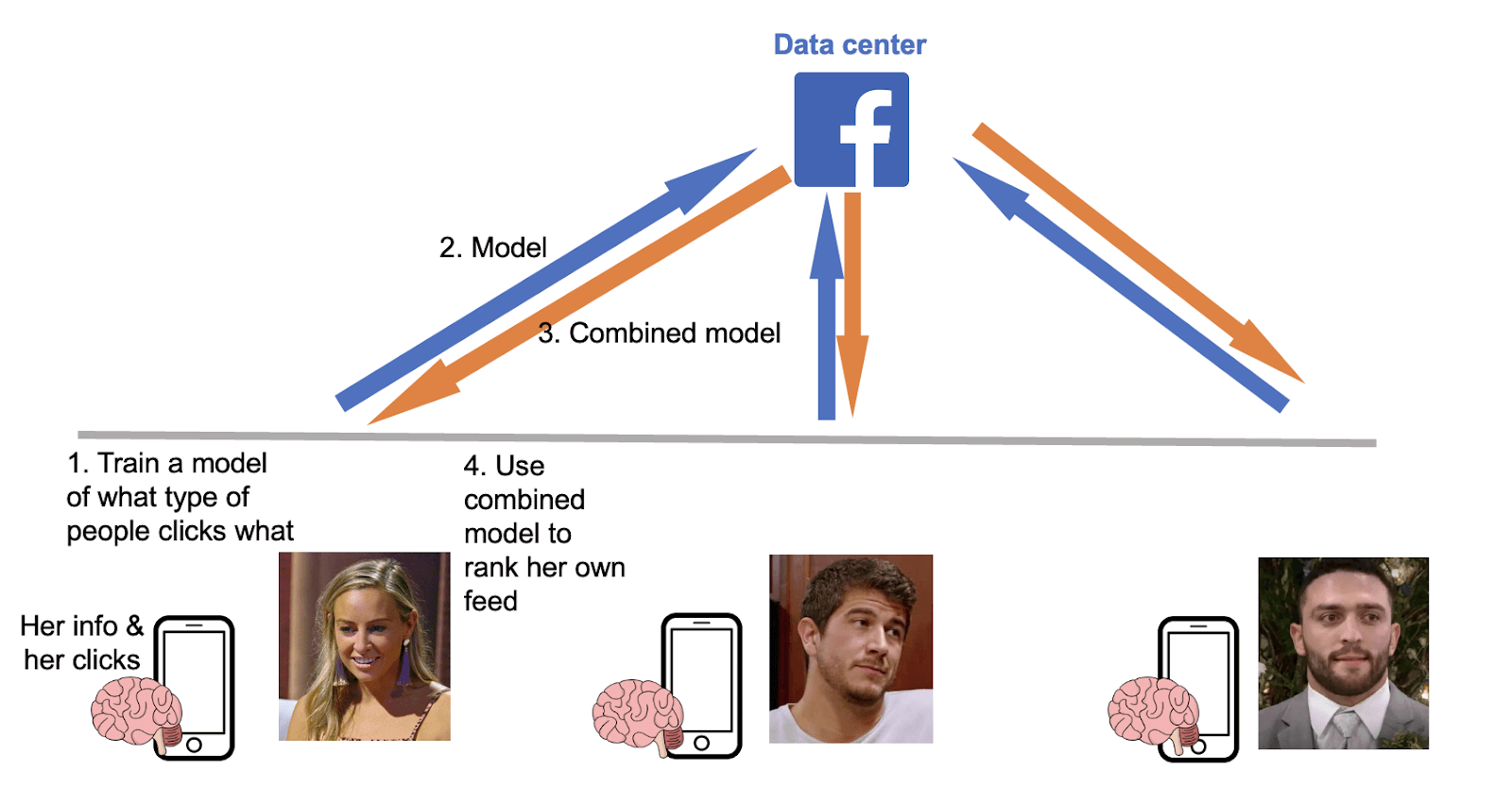
Step 1: You use Facebook and your device trains a model. Step 2: Your device shares only the model updates to a centralized server to be combined. Step 3: Your device receives the combined model. Step 4: Your device uses the combined model to rank your own newsfeed. With the properly secured aggregation methods, the corporation cannot reverse engineer the model to get your data.
Federated learning delivers the benefits of machine learning without forcing users to compromise their privacy. Like a federation of countries, each with its own autonomy, user’s devices have autonomy over their data. If you’re interested in learning more about players and applications of federated learning, check out Nicole Williams’ piece. For another primer on federated learning, check out Google’s comic. If you’d like to collaborate, discuss, or share thoughts about federated learning, my DMs and email inbox are open!